4 Quick Start: Project Directory Structure and Matlab Configuration
This section provides a quick-start summary for setting up your project directory structure and configuring Matlab to work with this structure.
You need the file path to your project root folder for these next steps. This project directory must be on your local computer: avoid putting it on an external drive or cloud drive (like OneDrive or GDrive) as this will cause problems in the steps that follow. Additionally, avoid putting it within the Biomet.net directory.
You will also need to create a site ID that relates to the flux site you are working with. This is often an acronym based on the site name (e.g., Burns Bog has siteID = 'BB', Richmond Brackish Marsh has siteID = 'RBM'). Note that the siteID must be all upper case.
Instructions
If you have multiple flux sites, choose one site to begin working with. Using the Matlab command line, define your projectPath and siteID as in the following example:
For example, if the name of your project is
My_Micromet, and your chosen siteID isSITEID1, you would enter the following commands in the Matlab command window:Mac example:
projectPath = '/Users/<username>/Projects/My_Micromet/'; siteID = 'SITEID1';
PC example:
projectPath = 'C:\Projects\My_Micromet\'; siteID = 'SITEID1';
Next, in Matlab, run the
create_TAB_ProjectFoldersfunction (which is in theBiomet.netlibrary that you cloned), as follows:create_TAB_ProjectFolders(projectPath,siteID)
Both input arguments are of type “string”. You can use single
''or double""quotation marks for these purposes in Matlab, although technically, these mean slightly different things; see this link for more info.As the function name suggests, this will create some folders on your computer, and also transfer some necessary small files. In your project root directory (e.g.,
My_Micrometin figure 4.1), you should now see three new directories with the following names: (1) Database, (2) Matlab, (3) Sites.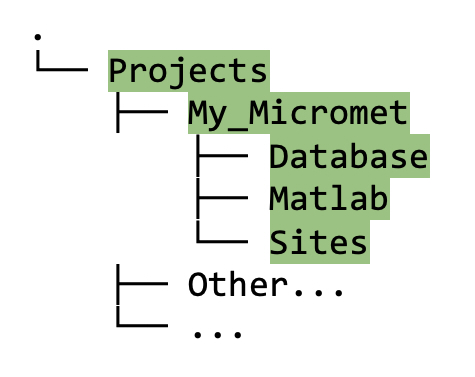
Figure 4.1. Directory tree showing contents of project folder after running the
create_TAB_ProjectFoldersMatlab function.[Note: if you are working with an earlier version of Matlab than 2023b, you may get an error when running
create_TAB_ProjectFolders(above). In that case, download this zip file, unzip, and put the contents of “My_Micromet_Folder” within your project directory (underneathMy_Micromet); make sure your directory structure looks like figure 4.1.]Finally, run
set_TAB_project(projectPath). This process sets up theBiomet.nettoolbox to work with your project.
Short description of new directory structure and contents
For now we will describe only the new directories and files necessary for you to begin data cleaning.
Database directory
The new
Databasedirectory contains aCalculation_Proceduresdirectory, and withinCalculation_Procedures, there is one calledTraceAnalysis_ini.Within
TraceAnalysis_ini, you will see a subdirectory named using your siteID (e.g.,SITEID1in figure 4.2), as follows: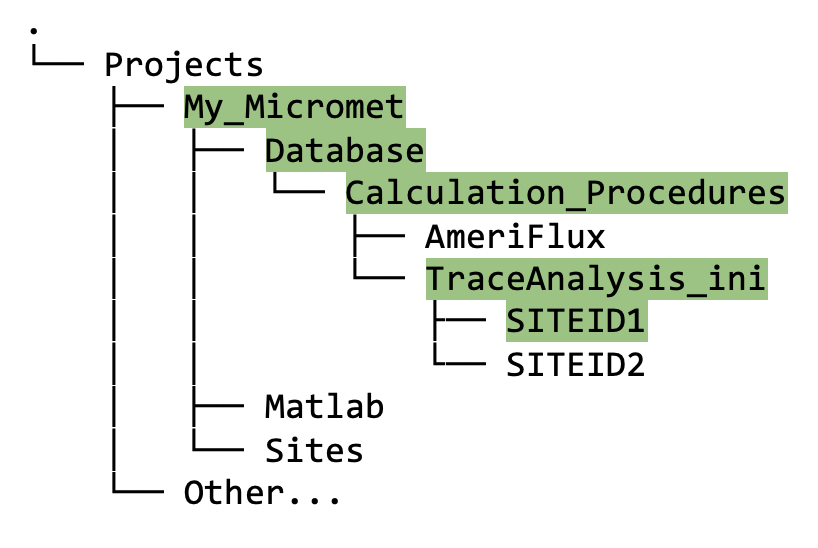
Figure 4.2. Directory tree showing contents of
TraceAnalysis_inifolder after running thecreate_TAB_ProjectFoldersMatlab function.Eventually (but not yet!), this
Databasedirectory will also contain the following:- Initial database created using your raw data;
- Your site-specific INI files that configure how the pipeline scripts will clean the data;
- The cleaned data once the INI files have been created and the pipeline has been run.
Sites directory
Raw, uncleaned data from your site(s) will be stored in the
<projectPath>/Sitesdirectory, under the appropriate siteID (covered shortly in section 5.1). The data in this directory should remain untouched since we always want to preserve a copy of the raw data.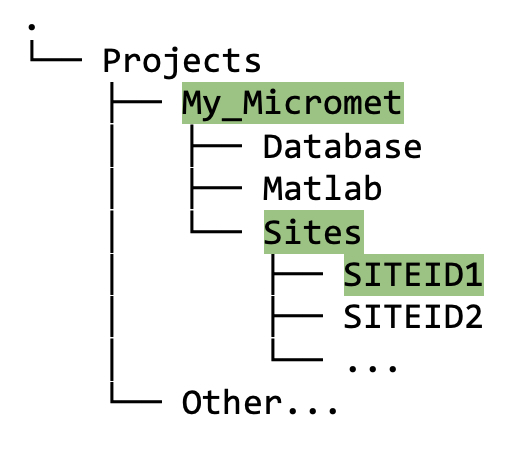
Figure 4.3. Directory tree showing contents of
Sitesfolder after running thecreate_TAB_ProjectFoldersMatlab function.
Matlab directory
- This directory should now contain three matlab files:
-
get_TAB_project_configuration.mwhich was created “behind the scenes” in step 2 above, then used during step 3; -
biomet_database_default.m; and -
biomet_sites_default.m.
-
The latter two functions are used in the pipeline behind the scenes, and may also be useful to you later when you want to visualize your data.