7. Troubleshooting, FAQ, and Special Cases
On this page:
- Troubleshooting: some general tips
- FAQ
- Creating one database from multiple files.
- Adding further flux sites to one project after first site is set up.
- Multiple date ranges for different sensors applied to one unique variable.
- Including data from nearby climate stations for gap-filling.
- Third stage finishing within seconds.
- Helping Matlab to locate R on your computer.
- Informing pipeline of data frequency, e.g., 10 Hz or 20 Hz.
- Determining which existing variables contain all NaNs.
- Remove time period from data, for all or a subset of traces.
- Special Cases
- Ignoring variables that have no raw input data but are defined in INI include files.
- Creating a project with older Matlab versions than 2023b.
- Issues with upper/lower case on Linux operating system.
- Creating INI files from Ameriflux or other generic network data.
This section presents some general troubleshooting tips outlining things to check to make sure the pipeline scripts will run smoothly, as well as FAQ, and some guidance on special cases and how to handle them.
Note that this page will continue to be updated as the pipeline is further developed and tested.
Troubleshooting: some general tips
- Before running data cleaning, first make sure you have the most recent version of the
Biomet.netlibrary (see section 2.2 for details). The code is updated regularly and you should be updating your local repository at least once per week. If you downloaded the Biomet.net library (rather than cloned it), make sure that you renamed it exactly asBiomet.netsince the download includes “main” in the folder name. - When running data cleaning (any stage), pay very close attention to the output on your screen. It tells you when everything runs smoothly, and if something goes wrong, in most cases it will be informative as to why and whereabouts things went wrong.
- Avoid having extra white space in your INI file between
[TRACE]and[END]. Each parameter must be defined on a new line, with no wraparound. We recommend using a text editor that has line numbers (such as VS Code) to help you avoid and/or diagnose this issue.
FAQ
I have multiple files containing data from one site, e.g., daily, monthly, or annual files. How do I create one database from all my files?
- See section 5.2: subsection “Create Database from Multiple Input Files and Updates for Continuous Operational Sites”.
I have multiple flux sites. Once I’ve added one site and created my database with data from that site (and cleaned it, etc.), what are the steps to move on to my next site?
create_TAB_ProjectFoldershas a third optional input argument,flagAddingSiteOnly. After setting up your project with your first flux site, define your second site ID, then set this argument to TRUE (or ‘1’). Here is an example of code to create a project from scratch and then add a second site:
% Define project path and first site ID projectPath = '/Users/<username>/Projects/test-project/'; siteID = 'SITEID1'; % Create project create_TAB_ProjectFolders(projectPath,siteID); % Define second site ID siteID = 'SITEID2'; % Add site only using same function create_TAB_ProjectFolders(projectPath,siteID,1);I replaced my 2-m air temperature (or any other) sensor; how do I tell Matlab to read multiple date ranges, one for each sensor?
- Use the
inputFileNameandinputFileName_datesparameters, with the syntax as in the following example, showing three different sensors with their respective date ranges:
variableName = 'TA_1_1_1' title = 'Air temperature at 2m (HMP)' originalVariable = 'Air temperature at 2m (HMP)' inputFileName = {'MET_HMP_T_2m_Avg','LI7700_Tair','MET_HMP155_2m'} inputFileName_dates = [datenum(2010,1,1) datenum(2020,1,1);datenum(2020,1,1) datenum(2024,1,1);datenum(2024,1,1) datenum(2999,1,1)] measurementType = 'met' units = '∞C' instrument = 'HMP155A' ...- Use the
How do I incorporate data from other sources such as nearby climate stations, e.g., for gap-filling, into my database?
- See section 5.2: subsection “Create Database Using Data from Canadian Meteorological Stations”.
When I run third stage cleaning, why does it finish so quickly (less than a minute), and/or why is there is no data output in the
Databasedirectory?Check the log file that is produced automatically when running the third stage (
SITEID1_ThirdStageCleaning.log). It is informative and will usually tell you the issue; it is located here: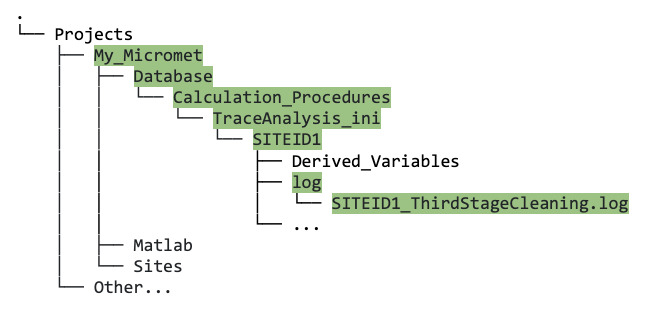
Screenshot showing the location of the third stage log file.
Check that all R packages are installed and loaded. Refer to the code provided in section 2.5 for this.
Check that after you downloaded and unzipped the
Biomet.netlibrary, you renamed it fromBiomet.net-maintoBiomet.net.
Matlab cannot find R/Rscript on my computer, even though it is installed with the correct versions. How do I fix this?
Create a function called
biomet_Rpath_default.mand put it in your project Matlab folder. You can explicitly define the path to the Rscript executable file, like in the example below:Mac example:
function folderR = biomet_Rpath_default folderR = '/usr/local/bin/Rscript';
Windows example:
function folderR = biomet_Rpath_default folderR = 'C:\Program Files\R\R-4.4.1\bin\Rscript.exe';
This can happen if R and/or Matlab are not both in “Program Files” folder, on Windows.
My raw eddy-covariance data has a frequency of 10 Hz (rather than 20 Hz): how do I tell the pipeline to utilize this information in the diagnostics, used records and file records?
- In your
SITEID1_FirstStage.inifile, you can use global variables to overwrite diagnostic settings defined in include files (see section 5.3: subsection Global variables and include files), as follows:%--> For specifying minMax number of used records and file records depending on frequency, e.g.: % Example: globalVars.Trace.used_records.minMax = [1500*frequency 1800*frequency] %(where frequency is typically 10 or 20 Hz) globalVars.Trace.used_records.minMax = [15000 18000] globalVars.Trace.file_records.minMax = [15000 18000]
- In your
Is there a fast way to check whether variables loaded into my database actually contain data (or if all data points are NaN)?
- Yes. Call the following function by giving it siteID, year, and cleaning stage number (1 or 2), and it will return the names of all traces from that stage that contain no other numbers but NaNs:
cntAllNanFiles = findAllNaNfiles('DSM',2025,1); - Alternatively, you can just point it to a folder with database files without specifying anything else:
cntAllNanFiles = findAllNaNfiles('E:\Pipeline_Projects\database\2024\DSM\Clean\SecondStage'); - Sample output:
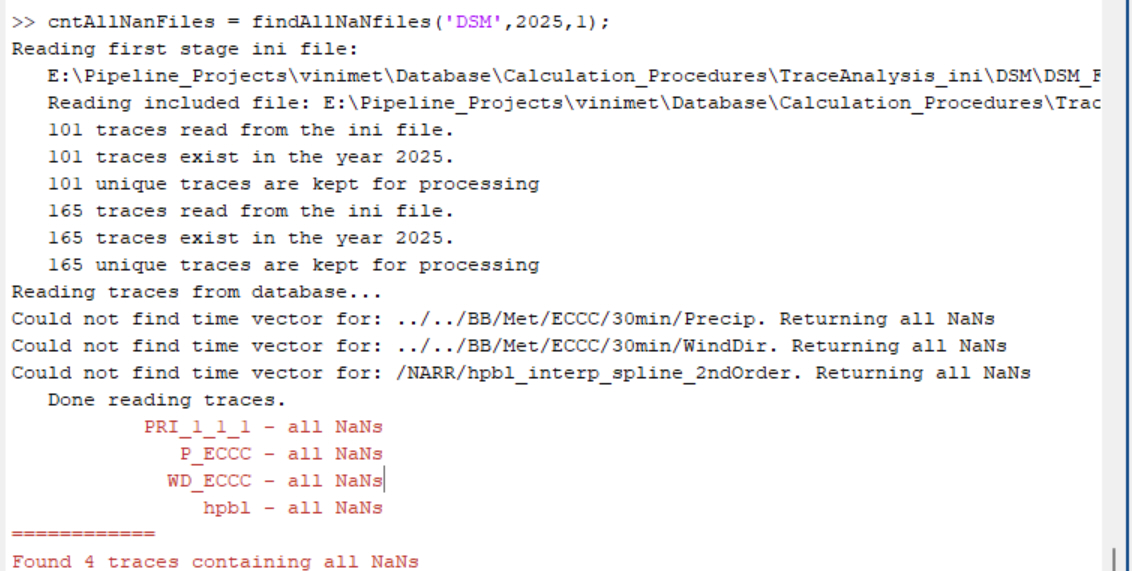
- Yes. Call the following function by giving it siteID, year, and cleaning stage number (1 or 2), and it will return the names of all traces from that stage that contain no other numbers but NaNs:
How do I remove a specific time period from my data?
To remove data within a time period:
In your first stage INI file, use the following code to create a trace called ‘flag_Kill_TimePeriod’, or similar. You will also need to define a time vector trace ‘clean_tv’ (defined first in this code snippet), if it does not already exist.
The first code block example removes data for 3 January 2025; adjust this as needed using the datetimes in the ‘Evaluate’ parameter.
If you wish to remove data for specific traces you should change the ‘dependent’ parameter in the ‘flag_Kill_TimePeriod’ trace from ‘tag_All’ to the relevant variable names.
% Load time vector clean_tv [Trace] variableName = 'clean_tv' title = 'Testing' inputFilename = {'clean_tv'} inputFileName_dates = [] measurementType = 'Flux' units = '' instrument = '' instrumentSN = [] loggedCalibration = [] currentCalibration = [] comments = 'Load time vector so that it becomes available for Evaluate calculations' minMax = [Inf, Inf] zeroPt = [-9999] dependent = '' [End] [Trace] variableName = 'flag_Kill_TimePeriod' title = 'Testing' inputFileName = {'clean_tv'} inputFileName_dates = 'Flux' units = '' instrument = '' instrumentSN = '' loggedCalibration = [] currentCalibration = [] comments = 'Remove ALL data from Jan 3, 2025' minMax = [-Inf,Inf] zeroPt = [-9999] Evaluate = 'flag_Kill_TimePeriod = ones(size(clean_tv)); flag_Kill_TimePeriod(clean_tv>datenum(2025,1,3) & clean_tv <= datenum(2025,1,4)) = NaN;' dependent = 'tag_All' [End]To remove data outside a time period:
- The code snippet below will remove all data prior to September 2021:
[Trace] variableName = 'flag_Kill_TimePeriod' title = 'Testing' inputFileName = {'clean_tv'} inputFileName_dates = 'Flux' units = '' instrument = '' instrumentSN = '' loggedCalibration = [] currentCalibration = [] comments = 'Remove ALL data BEFORE September 2021' % minMax needs to be entered as Matlab datenum like this: minMax = [datenum(2021,9,1) datenum(2099,12,31)] zeroPt = [-9999] dependent = 'tag_All' [End]
Special Cases
This section outlines some recurring special cases and how to deal with them:
There is a variable defined in an include INI file that I have no raw input data for.
In this case, you can add the following code to the global variables section of your first stage INI file. Remember to change the name of the “dummyVariable” to match the name of the variable you do not have.
%-->Avoiding errors due to missing input files dateRangeNoData = [datenum(1900,1,1) datenum(1900,12,31)] globalVars.Trace.dummyVariable.inputFileName_dates = dateRangeNoData
E.g., if you are running data cleaning for the year 2023, this code essentially tells the pipeline that for this “dummyVariable”, no data exists for 2023 (and only exists for the year 1900), and the program will continue smoothly with no errors.
I am using an earlier version of Matlab than 2023b, and I’m getting an error when running the
create_TAB_ProjectFoldersfunction. How do I fix this?Download this zip file, unzip, and put the contents of the unzipped directory within your own project directory; make sure your directory structure looks like figure 4.1 in section 4.
The
gitcloneMatlab function is used within thecreate_TAB_ProjectFoldersfunction to transfer (clone) the directory structure and files within. However,gitclonewas only added to Matlab 2023b, so you need to download this project directory structure directly.If it is an error related to
gitclone, the error will occur on the line that gitclone is called, so you can check this in the error message, e.g., it may look like this:Error: File: create_TAB_ProjectFolders.m Line: 66 Column: 32 Incorrect use of '=' operator. To assign a value to a variable, use '='. To compare values for equality, use '=='.
I am working on a Linux operating system and first stage cleaning crashes with an error unable to open the “Met” or “Flux” database folder, e.g.:
*** Error! File: ".../Database/2024/RBM/met/Clean/TA_1_1_1" cannot be opened!
This is because the
measurementTypeparameter in your first stage INI file has lower case. To fix this, make sure that you are using upper case for themeasurementTypeparameter everywhere it appears in your first stage INI, e.g.,measurementType = 'Met'ormeasurementType = 'Flux'.I am starting with a “clean” data set, for example from Ameriflux or ICOS. Is there a quick or generic way to create INI files directly from this data to get it into the pipeline to run third stage/gap-filling?
Yes, we have a generic way of doing this, and one specifically designed for data downloaded from Ameriflux (BASE and BIF).
Usually, these input files have a small number of traces (<100) and they don’t need to use our “include” files.
Once the INI files are created, they can be edited to include some additional cleaning or data manipulation.
Generic solution:
- First convert the input (usually CSV) files to our database format (see sections 4.2/5.2).
- Run the code below, after editing the inputs to match your site. In particular, make sure you get the siteID and the startYear right.
startYear = 2021; siteID = 'mySite' GMT_offset = -8; % Set input parameters: structSetup.startYear = startYear; structSetup.startMonth = 1; structSetup.startDay = 1; structSetup.endYear = 2999; structSetup.endMonth = 12; structSetup.endDay = 31; structSetup.Site_name = 'Long name here'; structSetup.siteID = siteID; structSetup.allMeasurementTypes = {'Flux'}; structSetup.Difference_GMT_to_local_time = -GMT_offset; % local+Difference_GMT_to_local_time -> GMT time structSetup.outputPath = []; % keep it in the local directory structSetup.isTemplate = false; % Set to false if you want to create % create template: createFirstStageIni(structSetup) % SecondStage template: createSecondStageIni(structSetup)Ameriflux solution:
- Edit site ID(s), data source path (where you put your downloaded Ameriflux data), and project path as necessary.
% Convert Ameriflux BASE+BIF files into TAB database project % Example: creating a new project with two sites: allNewSites = {'BR-Npw','CA-BOU'}; dbID = 'AMF'; sourcePath = 'E:\Pipeline_Projects\Ameriflux_raw'; projectPath = 'E:\Pipeline_Projects\Ameriflux_CH4_v2'; flagNewSites = false; result = convertAmeriflux2TAB(allNewSites,dbID,sourcePath,projectPath,flagNewSites);% Example: adding a new site to an existing project allNewSites = {'CA-DSM'}; dbID = 'AMF'; sourcePath = 'E:\Pipeline_Projects\Ameriflux_raw'; projectPath = 'E:\Pipeline_Projects\Ameriflux_CH4_v2'; flagNewSites = true; result = convertAmeriflux2TAB(allNewSites,dbID,sourcePath,projectPath,flagNewSites);- If you use this method, you must ensure that you edit the resulting first and second stage INI files giving the following variables positional qualifiers ready for third stage processing/filtering: TA, RH, VPD, SW_IN, WD. The variable names must match the inputs you provide in your site-specific YAML file.
I have missing nighttime incoming shortwave radiation (SW_IN). Is there a way to gap-fill this data?
- Yes. In your second stage INI, use the following code to substitute the estimated global potential radiation during nighttime, which in this example is when global_potential_radiation < 5 W/m^2. You can always edit this threshold. If you are not using the radiation include file (RAD_FirstStage_include.ini) you will also need to define the ‘global_potential_radiation’ trace, otherwise leave this out.
[Trace] variableName = 'global_potential_radiation' title = 'Calculate potential radiation' inputFileName = {'clean_tv'} inputFileName_dates = [] measurementType = 'met' units = '' instrument = '' instrumentType = '' instrumentSN = '' Evaluate = 'lat = configYAML.Metadata.lat; long = configYAML.Metadata.long; longW = -long; TimeZoneHour = configYAML.Metadata.TimeZoneHour; GMT = clean_tv - (TimeZoneHour/24); global_potential_radiation = potential_radiation(GMT,lat,longW); loggedCalibration = [] currentCalibration = [] comments = 'Above assumes TimeZoneHour in YAML file is negative west of prime meridian. We need to make sure this is standardized. The function potential_radiation() assumes longitude west of prime is positive.' minMax = [0,1361] zeroPt = [-9999] dependent = '' [End] [Trace] variableName = 'SW_IN_1_1_1' title = 'Shortwave radiation, incoming' units = 'W m-2' Evaluate = 'flag = (global_potential_radiation < 5); SW_IN_1_1_1(flag) = global_potential_radiation(flag);' [End]